
Llama(ラマ)とはLarge Language Model Meta AIの略で、FacebookやInstagramで知られるMeta社が開発した大規模言語モデル(LLM)です。
Llama2(ラマツー)では、パラメータ数が70億・130億・700億という3つのモデルがあり、事前学習済みバージョンとチャット用のファインチューニングされたものの2タイプが用意されています。
それでは早速Macbook Pro (M1)でLlama2を動かしてみましょう。
実行環境
今回の記事は、こちらの環境で実行しています。
- MacBook Pro
- チップ Apple M1 Pro
- メモリ 32GB
インストールとビルド
MacBookでLlamaを実行することを目指して開発されたランタイムLlama.cppを使っていきましょう。
初めに必要なパッケージをインストールし、ビルドします。
% brew install wget git cmake% xcode-select --install% git clone https://github.com/ggerganov/llama.cpp
% cd llama.cpp
% make
補足:2025年4月の最新バージョンでは、makeをすると以下のエラーが発生します。
% make
Makefile:2: *** The Makefile build is deprecated. Use the CMake build instead. For more details, see https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md. Stop.
その際は、次のコマンドを実行してください。
% cmake -B build
% cmake --build build --config Release
モデルのダウンロード
ここでは70億パラメータのチャットモデルを例に使っていきます。
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/tree/main から”Files and Versions”を選択し、お勧めのllama-2-7b-chat.Q4_K_M.ggufをダウンロードしてみましょう。
% cd models% curl -O -L https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q4_K_M.gguf
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1157 100 1157 0 0 4428 0 --:--:-- --:--:-- --:--:-- 4432
100 3891M 100 3891M 0 0 7481k 0 0:08:52 0:08:52 --:--:-- 8815k コマンドから実行
早速コマンドから指示を出してみましょう。
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/blob/main/README.md にサンプルがあるので、詳細を確認したい場合はチェックしてみてください。
では、実際に試してみましょう。
% ./main -ngl 32 -m ./models/llama-2-7b-chat.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>nPlease tell me 3 reasons why we need to learn AI?n<</SYS>>n{prompt}[/INST]"
Log start
main: build = 2311 (9bf297a0)
main: built with Apple clang version 15.0.0 (clang-1500.1.0.2.5) for arm64-apple-darwin23.3.0
main: seed = 1709392384
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from ./models/llama-2-7b-chat.q4_K_M.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 10: general.file_type u32 = 15
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q4_K: 193 tensors
llama_model_loader: - type q6_K: 33 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 3.80 GiB (4.84 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.22 MiB
ggml_backend_metal_buffer_from_ptr: allocated buffer, size = 3820.92 MiB, ( 3820.98 / 21845.34)
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloaded 32/33 layers to GPU
llm_load_tensors: Metal buffer size = 3820.92 MiB
llm_load_tensors: CPU buffer size = 3891.24 MiB
.................................................................................................
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M1 Pro
ggml_metal_init: picking default device: Apple M1 Pro
ggml_metal_init: default.metallib not found, loading from source
ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil
ggml_metal_init: loading '/Users/skito/my_env/llama.cpp/ggml-metal.metal'
ggml_metal_init: GPU name: Apple M1 Pro
ggml_metal_init: GPU family: MTLGPUFamilyApple7 (1007)
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
ggml_metal_init: simdgroup reduction support = true
ggml_metal_init: simdgroup matrix mul. support = true
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: recommendedMaxWorkingSetSize = 22906.50 MB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 2048.00 MiB, ( 5870.80 / 21845.34)
llama_kv_cache_init: Metal KV buffer size = 2048.00 MiB
llama_new_context_with_model: KV self size = 2048.00 MiB, K (f16): 1024.00 MiB, V (f16): 1024.00 MiB
llama_new_context_with_model: CPU input buffer size = 17.04 MiB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 296.02 MiB, ( 6166.81 / 21845.34)
llama_new_context_with_model: Metal compute buffer size = 296.00 MiB
llama_new_context_with_model: CPU compute buffer size = 78.50 MiB
llama_new_context_with_model: graph splits (measure): 3
system_info: n_threads = 8 / 10 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 |
sampling:
repeat_last_n = 64, repeat_penalty = 1.100, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.700
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampling order:
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temperature
generate: n_ctx = 4096, n_batch = 512, n_predict = -1, n_keep = 1
[INST] <<SYS>>nPlease tell me 3 reasons why we need to learn AI?n<</SYS>>n{prompt}[/INST] Sure! Here are three reasons why learning AI is important:
1. Automation and Efficiency: AI can automate many repetitive and mundane tasks, freeing up time for more creative and strategic work. By leveraging AI, businesses and organizations can streamline their operations, improve productivity, and reduce costs. For example, chatbots and virtual assistants can handle customer service inquiries, while machine learning algorithms can analyze large datasets to identify patterns and make predictions.
2. Data Analysis and Insights: AI can process and analyze vast amounts of data much faster and more accurately than humans. By applying machine learning algorithms to data, businesses can gain valuable insights into customer behavior, market trends, and operational performance. This can help them make informed decisions, identify new opportunities, and improve their overall competitiveness.
3. Innovation and Competitive Advantage: AI is revolutionizing many industries, from healthcare to finance to transportation. By leveraging AI, businesses can create new products and services that were previously impossible, or offer existing ones in a more innovative and efficient way. This can help them gain a competitive advantage over their rivals and stay ahead of the curve in a rapidly changing market.
In summary, learning AI can help individuals and organizations automate tasks, analyze data, and innovate new products and services, leading to increased efficiency, productivity, and competitiveness. [end of text]
llama_print_timings: load time = 5216.27 ms
llama_print_timings: sample time = 25.70 ms / 316 runs ( 0.08 ms per token, 12294.28 tokens per second)
llama_print_timings: prompt eval time = 373.03 ms / 40 tokens ( 9.33 ms per token, 107.23 tokens per second)
llama_print_timings: eval time = 11020.17 ms / 315 runs ( 34.98 ms per token, 28.58 tokens per second)
llama_print_timings: total time = 11467.97 ms / 355 tokens
ggml_metal_free: deallocating
Log end
WEB UIから実行
ターミナルから次のコマンドを実行してください。
% pip install streamlit langchain replicate % git clone https://github.com/facebookresearch/llama-recipes % cd llama-recipes/demo-apps
streamlit_llama2.pyの<your replicate api token>をhttps://replicate.com/account/api-tokensで作成したトークン置換してください。
% streamlit run streamlit_llama2.py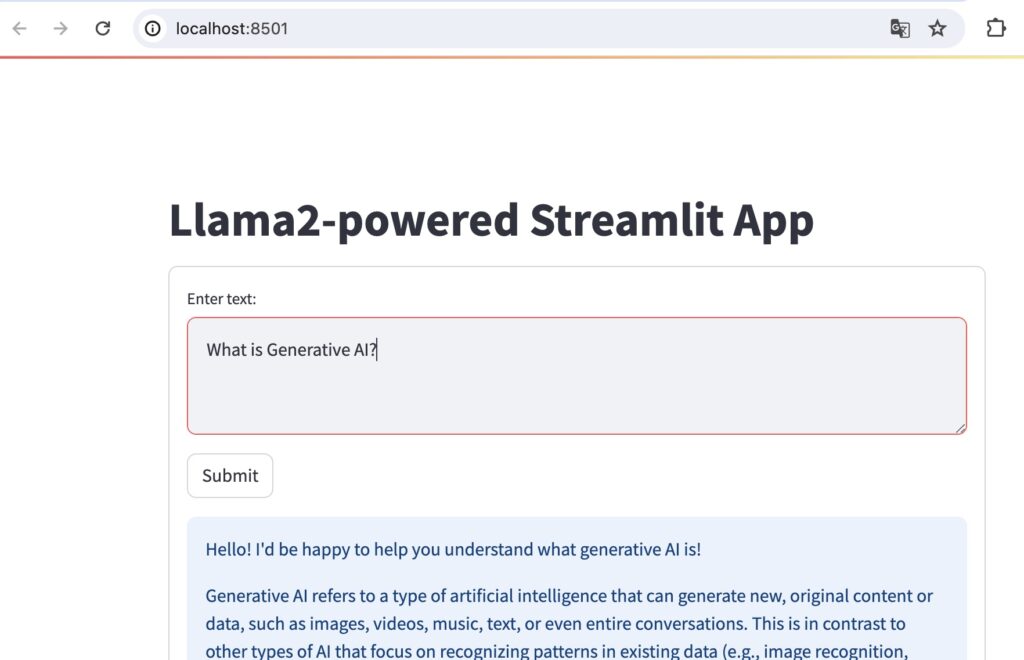

コメント