
前回は、クラス分類をするためにScikit-LearnのSGDというライブラリを使って数字の画像データの判定を行った。
今回は、結果がどれほど正しいかについて検証するための関数について学んでみよう。
Cross Validationとは
Cross Validationとは、機械学習のモデルがホントにどれほど実用的かどうかをチェックする方法だ。
日本語では、交差検証ともいう。
ざっくりいうと、データを分割し、その一部をまず解析して、残る部分でその解析のテストを行い、解析自身が問題ないかチェックする手法だ。
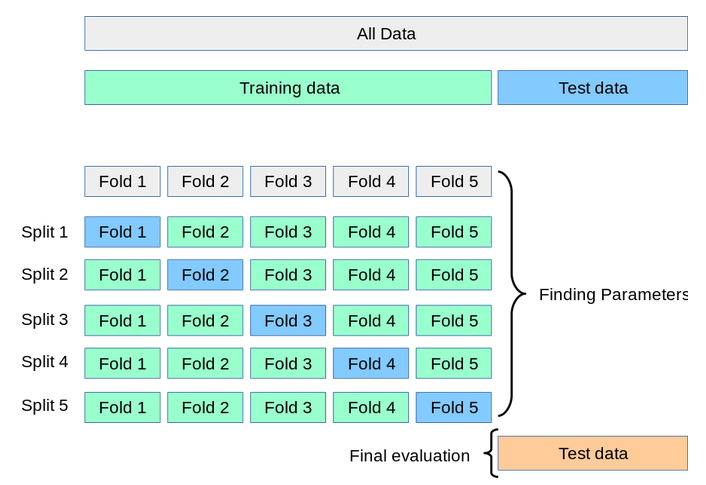
k-folds cross validationという検証方法についてみてみよう。日本語では、K-分割交差検証というらしい。
例えばk=5とした場合、データを5分割して、20%のデータを検証用データセットとして、80%のデータを訓練用データセットとする。
訓練用のデータセットでモデルの学習をし、検証用データセットでモデルの性能を評価する。
これを5回繰り返して、性能の平均をとる。
cross_val_score()関数
forループで全てチェックするプログラムを書くこともできるが、すでにcross_val_score()関数があるので、こちらを利用しよう。cross_val_score()関数は、cv(何分割にするかという値)の数と同じ長さのnumpy.arrayを返す。
arrayの各値が、1回ごとに計算したスコアになる。
オンラインマニュアルによると、バージョン0.22からcvのデフォルトが3-foldから5-foldに変更になったようだ。よって、k=3を指定したい場合は、cv=3と指定しよう。
こちらが実行結果。

この結果から、94%以上の正答率と言えそうだが、ちょっと注意が必要だ。なぜなら、予測と実際の結果には、いくつかのパターンがあるからだ。
Confusion Matrix(混同行列)とは
Confusion Matrix(混同行列)とは、予測したクラスと実際のクラスの組み合わせによって、つぎの4パターンに分類することだ。

例えば、画像から5だと判定しても、実は3だったりすることがある。その場合は、False Positiveになる。
また性能評価指標には、つぎのパターンがある。
| 正解率(Accuracy) | (TP + TN) / (TP + FP + TN + FN) | 全てのデータで判定結果が合っていたかどうかを算出 |
| 適合率(Precision) | TP / (TP + FP) | 陽性であると予測したうち、実際に陽性である割合 |
| 再現率(Recall) | TP / (TP + FN) | 実際に陽性であるケースのうち、陽性と予測できた割合 |
比較してみよう
cross_val_predict()関数をつかって、予測をしてみよう。その後、confusion_matrix()関数で実際のクラスをチェックしよう。
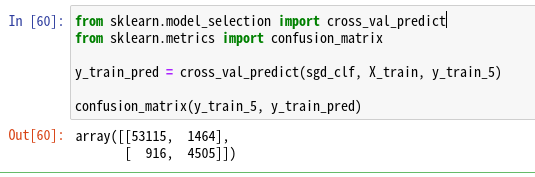
ちょっとわかりずらいが、結果はつぎの順番だ。
array([[tn, fp],
[fn, tp]])
つまり、53115はTNであり、正しく5でないと分類された。1464はFPであり、間違って5と分類された。916はFNであり、間違って5でないと分類された。4505はTPであり、正しく5であると分類された。
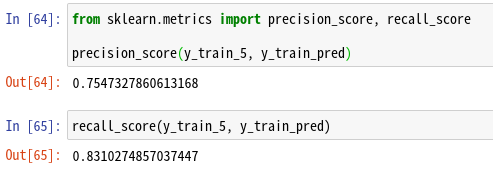
ここでPrecision(適合性)とRecall(再現性)について、Scikit-Learnで提供されている関数を使ってチェックしてみよう。
もう一度整理してみよう。
適合性が75.4%ということは、5と予測して、実際に5だった割合が75.4%ということだ。
再現性が83.1%ということは、実際に5であるのに、5と予測できた割合が83.1%ということだ。
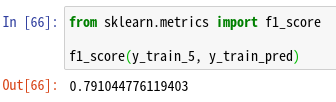
F1とは
F1とは、PrecisionとRecallの調和平均(harmonic mean)だ。scikit-learnには、f1_score()というメソッドが用意されているので、こちらを使おう。
注意点は、Precisionを上げるとRecallが下がる。いわゆる、Precision/Recallトレードオフだ。
まとめ
今回は機械学習の検証についていくつか学んだ。cross_val_core()関数を利用してチェックもできるが、そもそも0~9の10の数字のうち5だけチェックする場合、もともと5である割合は1割ぐらいなので、要注意だ。
そこで、Confusion Matirxをつかって、適合率(Precision)や 再現率(Recall)についても念の為チェックしてみた。
f1_score()をつかって、いわゆる調和平均を確認する方法もあるので、こちらも試してほしい。
10分でできるシリーズだが、長くなったので、今日はここまで。

コメント