
前回はPython3で環境の設定をしたので、さっそくデータをロードしてみよう。
今回は、1990年とちょっと古いカリフォルニアの家のデータを使って家の価格を予想するための準備をしてみよう。
Kaggleとは
Kaggleとは、世界中の統計家やデータ分析家がその最適モデルを競い合うプラットフォームだ。100万人以上のユーザが登録していて、194ヶ国でコミュニティーがあるそうだ。
2017年には、Googleによって買収されている。
今回はコンペに参加するのではなく、あくまで練習用にデータをダウンロードしてみよう。
上記の画像にあるように、https://www.kaggle.com/harrywang/housing/data?select=housing.csv からhousing.cvsをダウンロードできる。
This dataset appeared in a 1997 paper titled Sparse Spatial Autoregressions by Pace, R. Kelley and Ronald Barry, published in the Statistics and Probability Letters journal. They built it using the 1990 California census data. It contains one row per census block group. A block group is the smallest geographical unit for which the U.S. Census Bureau publishes sample data (a block group typically has a population of 600 to 3,000 people).
California Housing Data (1990)
データは、次の項目からなる。
- longitude
- latitude
- housing_median_age
- total_rooms
- total_bedrooms
- population
- households
- median_income
- median_house_value
- ocean_proximity
Ocean_proximityとは、海から近いかどうかという情報だ。
Jupyterからデータをみてみよう
ブラウザで、http://localhost:8888/tree を開き、New -> Python3を選んで、早速ダウンロードしたデータをロードしてみよう。
次のようなコードを In[]の右側に入力して、それぞれ実行してみよう。
import os
import pandas as pd
HOUSING_PATH = "Your_Path/my_env/datasets/housing"
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
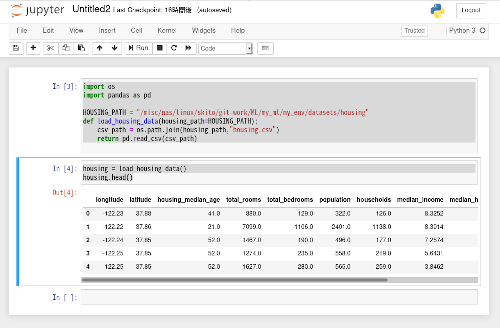
つづけて、最初の5つのデータを表示するコードがこちら。入力したら、Runをクリックして実行しよう。
housing = load_housing_data()
housing.head()
すると、次のような結果が表示されるはずだ。
Pythonコードの解説
Pythonのことを全く知らないあなた。
大丈夫。
ここでは、素人目線でPythonのコードも一緒に見てみよう。
import os
これは、OS(オペレーティングシステム)に依存した機能を使うためのライブラリだ。デフォルトでインストールされているので、すぐに使える。
import pandas as pd
Pandasとは、データ解析をかんたんにするライブラリだ。前回インストールしたので、利用できると思うが、もし見逃したら、https://wild-tech.jp/2020/06/11/543/ を参考にしてほしい。
asとは、その名のとおりライブラリに好きな名前をつけることができるものだ。
csv_path = os.path.join(housing_path,"housing.csv")
os.path.joinは、引数の2つの文字列を結合して、1つのパスにする命令だ。
pd.read_csv(csv_path)
pd.read_csvは、カンマ区切りのCSVファイルを読みたい時に使う。
housing.head()は、データの最初の5行だけ表示させ、最後の5行の場合は、.tail()を使おう。
まとめ
今回は、Kaggleとは何かをカリフォルニアの住宅のデータを例に簡単に紹介した。
また、データをダウンロードして、ロードする方法について手順をおってみた。
データのボリュームが大きいので、今回ははじめの5行だけ表示してみた。
次回は、もう少しデータの操作について追っていこう。

コメント