
前回は、ROC曲線の下のエリアのAUSについて求めてみた。
今までは、数字の画像が5かそれ以外だけを判断していた。
今回は、 機械学習の中で単純なKNeighborsClassifierを使って複数のクラスについて判断してみよう。
KNeighborsClassifierとは
KNeighborsClassifierとは、ある入力が与えられた時に、それに最も近いk個のデータの平均を予測値とするというものだ。
KNeighborsの背後にある原則は、新しい点に最も近い距離にある事前定義済みのトレーニングサンプルを見つけ、それらからラベルを予測することだ。
距離の算出には、一般的にユークリッド距離が使われる。つまり、人が定規で測るような二点間の「通常の」距離だ。
KNeighborsClassifierの位置付け
機械学習の問題を解決するうえで、その仕事に適した見積もりをどうやって見つけるのか、悩む人もいるだろう。
そこで、次のフローチャートは、大まかなガイドをユーザーに提供するように設計されているので、迷ったら参考にしてみよう。
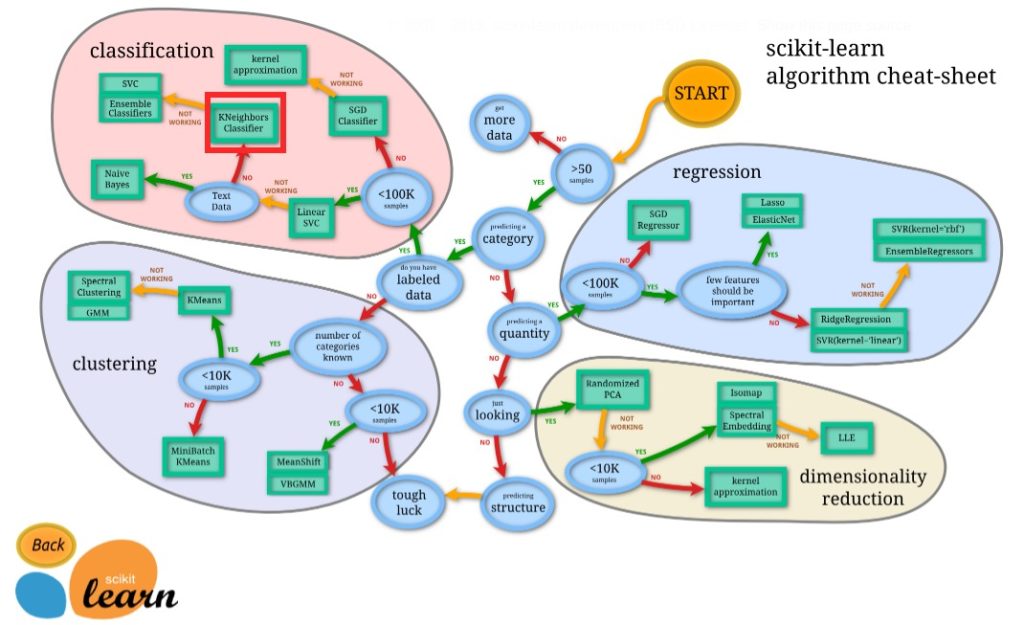
Nearest NeighborsのKNeighborsClassifierは、赤い枠で囲われたところだ。
学習し、予測してみよう
fit(training_data, target_value)でKNeighborsClassifierに基づき学習ができてしまう。非常にシンプルだ。
機械学習が完了したら、データを与えて、predict()を使って予測してみよう。
こちらが、サンプルコードだ。
ここでは、Numpyの配列結合のnp.c_を使って、y_train_large, y_train_oddを連結している。
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 6)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
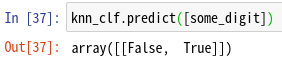
knn_clf.predict([some_digit])
some_digitは5なので、6より大きくないのでFalse、奇数なのでTrueとなり、正しい予測がされていることが確認できる。
では、予測について評価してみよう。
F値とは
F1スコアは、適合率(または精度)(Precision)と再現率(Recall)の加重平均で求めることができる。つまり、PrecisionとRecallをバランスよく持ち合わせているかを示す指標だ。
F1スコアは、1で最高値に達し、0で最悪スコアだ。
F1 = 2 * (precision * recall) / (precision + recall)
では、f1_score()を使って、F1値を求めてみよう。
from sklearn.metrics import f1_score
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3, n_jobs=-1)
f1_score(y_multilabel, y_train_knn_pred, average="macro")
corss_val_predict()のn_jobs=-1によって、全てのCPUを使って予測してみよう。
この計算は、時間がかかるので、しばらく待ってみよう。ちなみに、結果はこちら。

非常に、いい結果といえるだろう。
まとめ
分類にもいろいろなアルゴリズムがあるが、今回はKNeighborsClassifierを使ってみた。
上記のフローチャートを使って、そのほかのアルゴリズムも試してみよう。
また、F1値を求めることで、予測の評価も簡単にできる。


コメント