
前回は、データの最初の5行だけ表示したが、今回はもう少し詳しくみてみよう。
まずは、データの全体像を把握してみよう。それから、どのような分布になっているか探ってみよう。
info()メソッド
pandasのinfo()メソッドで、エントリー数、コラム、データの型、メモリの使用量などの情報が表示できる。
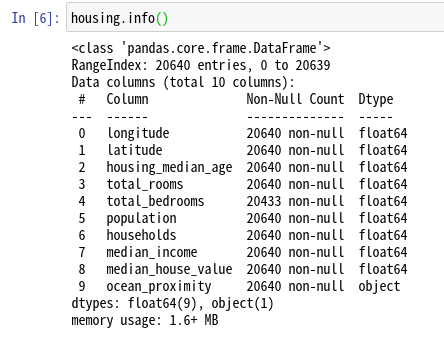
20,640のエントリーが含まれていることが確認できる。また、ベットルームだけは、20,433とデータの数が違うので、データが欠けていることがわかる。
Dtypeはデータの型のことで、float64は倍精度浮動小数点型でC言語ではdoubleにあたる。
objectは、データを抽象化したもので整数や文字列やリストなどのデータを指す。
describe()メソッド
describe()メソッドを使うと、数値に関する情報を表示できる。
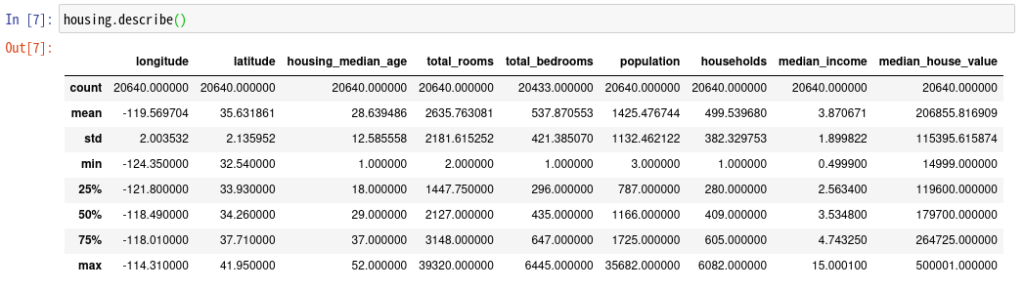
小数点以下の0が多くて見づらいけど、とりあえず気にせずに中身をチェックしてみよう。meanは、平均だ。stdは、standard deviation。つまり、標準偏差でデータのばらつきを表す。偏差値などで使われる数値だ。
housing_median_ageは、18年以下が25%を占め、29年以下が50%を占める。日本と比べると米国ではリフォームして住んだりするので、比較的長いと感じるだろう。
median_house_valueについても、$179,700が50%を占める。今では考えられないぐらいに安い。
show()メソッド
数値で全体像をつかむこともできるが、データの分布状況を視覚的にチェックしてみよう。次のコードを順にみていこう。
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=100, figsize=(20,15))
plt.show()
Matplotlibは、Pythonのグラフ描画ライブラリだ。使うには、1~2行目のようにライブラリをインポートしよう。Jupyter Notebookで、ノートブック上にグラフを描写するために必要だ。
histは、度数分布を表すヒストグラムだ。binsとは、等間隔の区分のことだ。数字を大きくすると、より細かいグラフになる。figsizeは、横幅と高さを指定できる。
では、binsが100と10を表示してみよう。
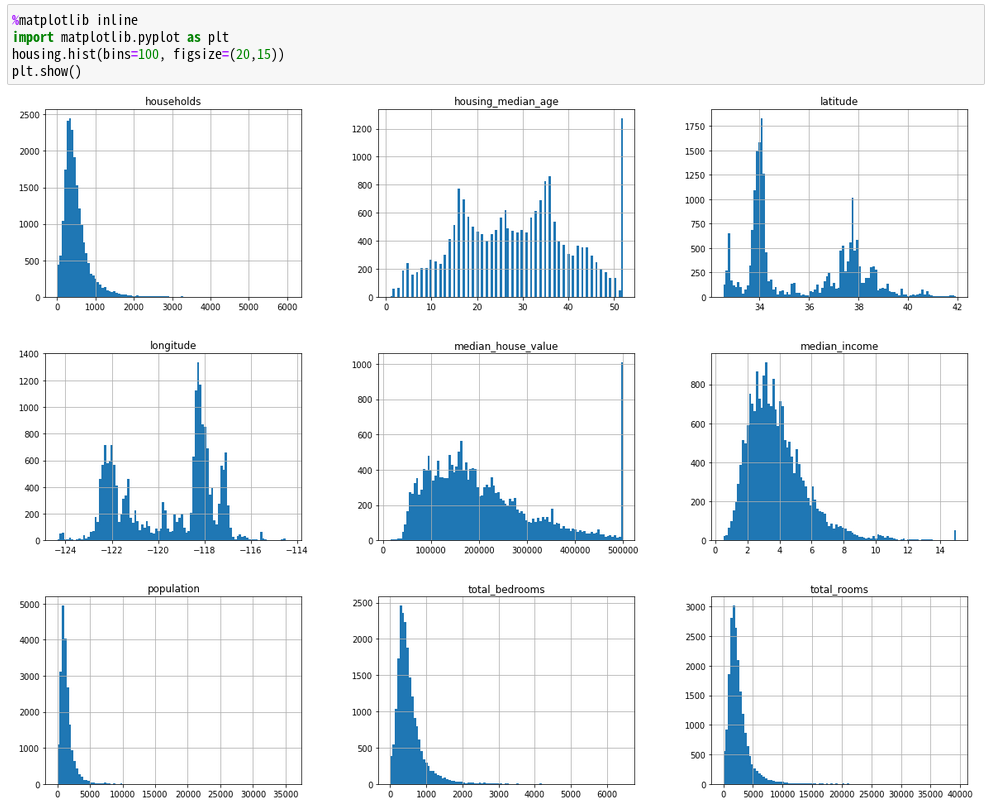
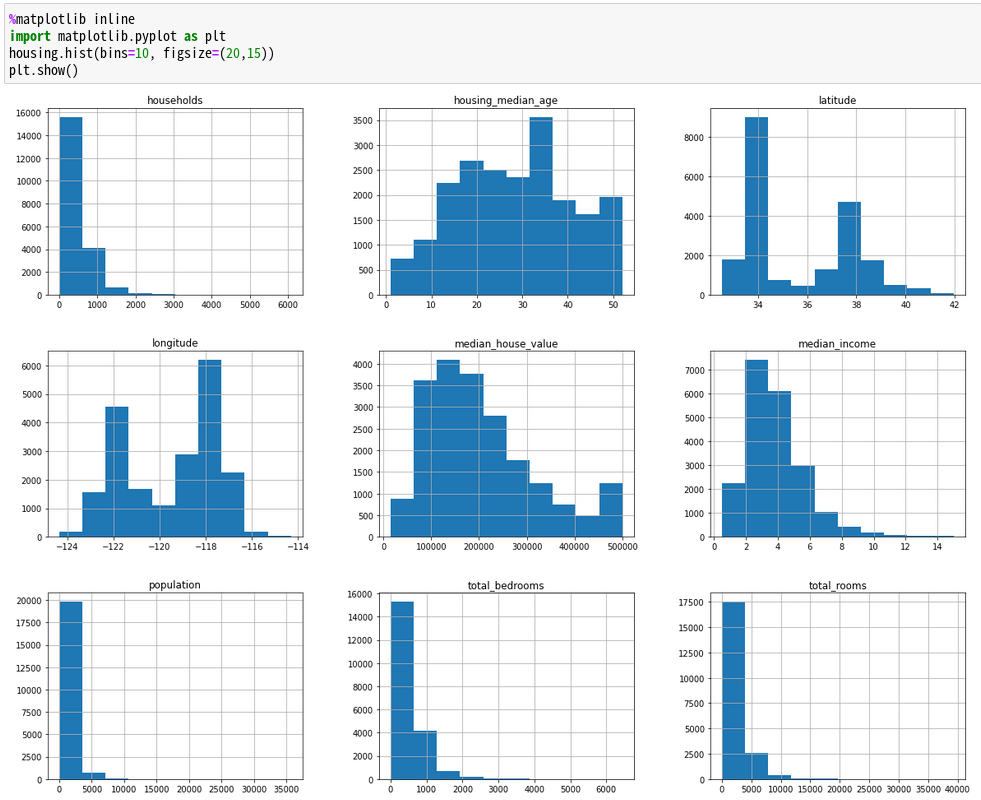
binsが10の方が大きなくくりになることがわかる。
グラフをみて気づいたかも知れないが、incomeが3の場合は$30,000を指す。これも昔のデータなので、今では生活できないレベルだ。
まとめ
pandasのinfo()メソッドを使って、ロードしたデータのエントリー数やコラム、データ型などの表示方法を学んだ。
数値に関するデータは、describe()メソッドによって統計情報を簡単に取得できる。
最後に、Matplotlibを使って、簡単にヒストグラムも表示できるようになった。

コメント